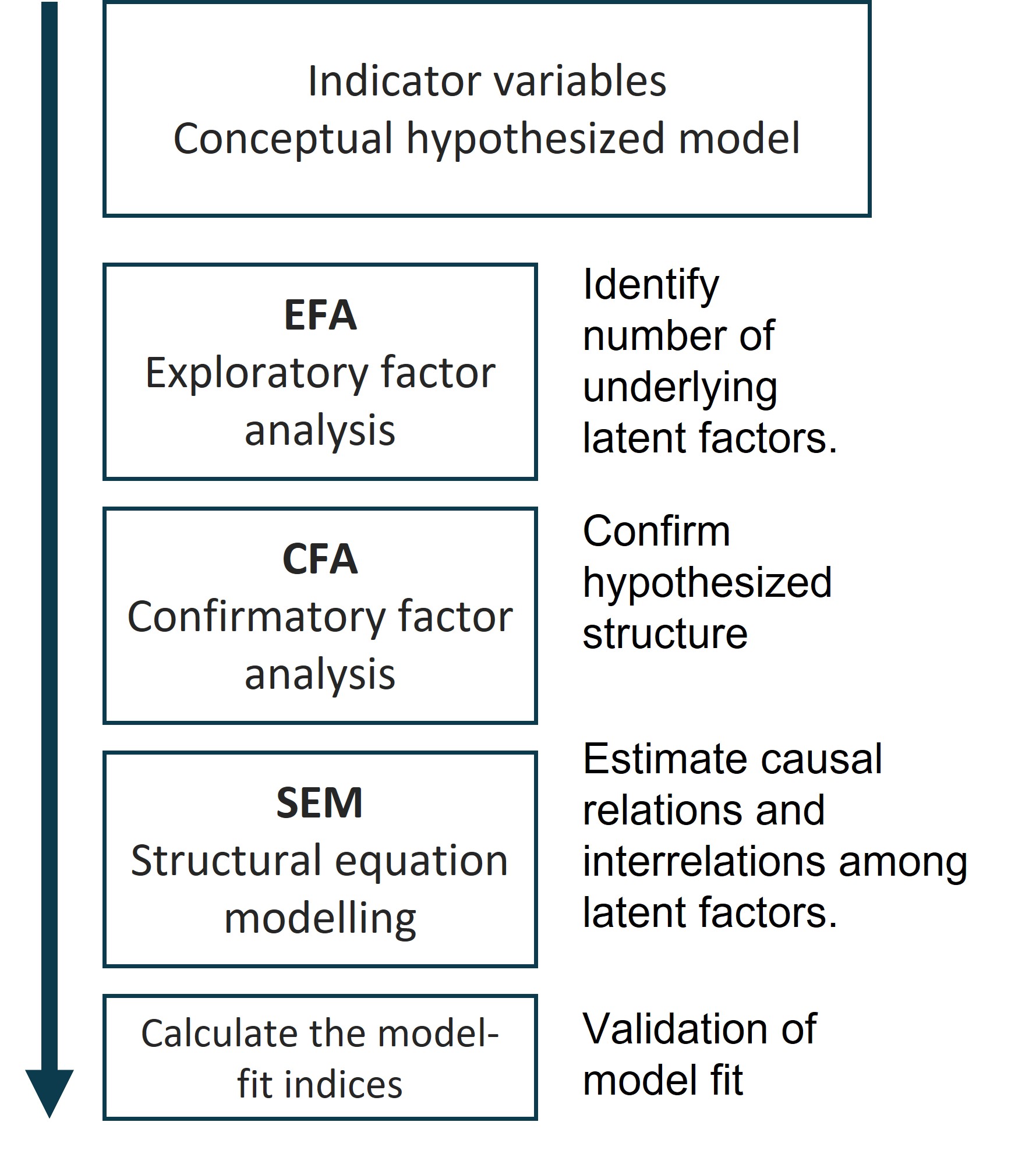
Training workshop on structural equation modelling (SEM) in R
Session 2: Exploratory Factor Analysis (EFA)
Sample Dataset
- HBAT Industries, manufacturer of paper products.
- Perceptions on a set of business functions.
- Rating scale:
0 "poor"to10 "excellent"

Partitioning the variance of a variable
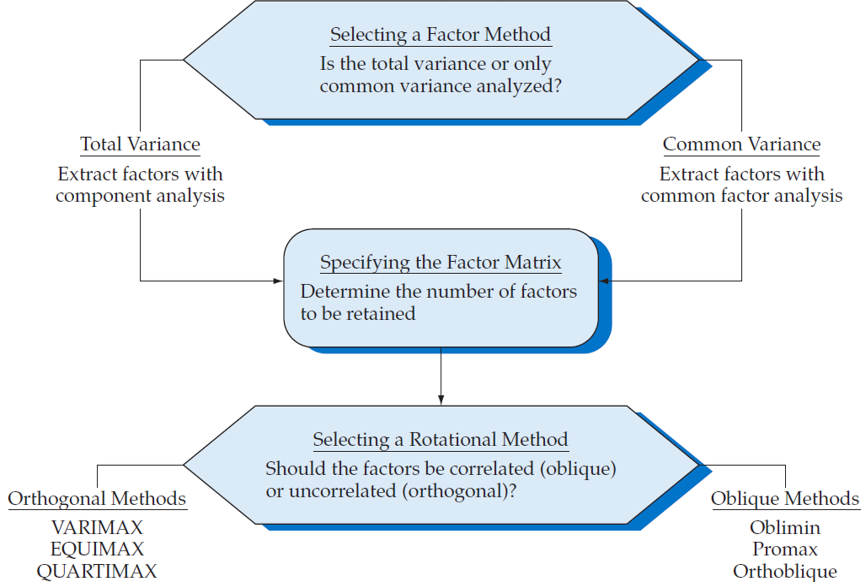
PCA vs Common factor analysis
Principal component analysis (PCA)
- Considers the total variance
- data reduction is a primary concern
Common factor analysis
- Considers only the common variance or shared variance
- Primary objective is to identify the latent dimensions or constructs

Exploring possible factors
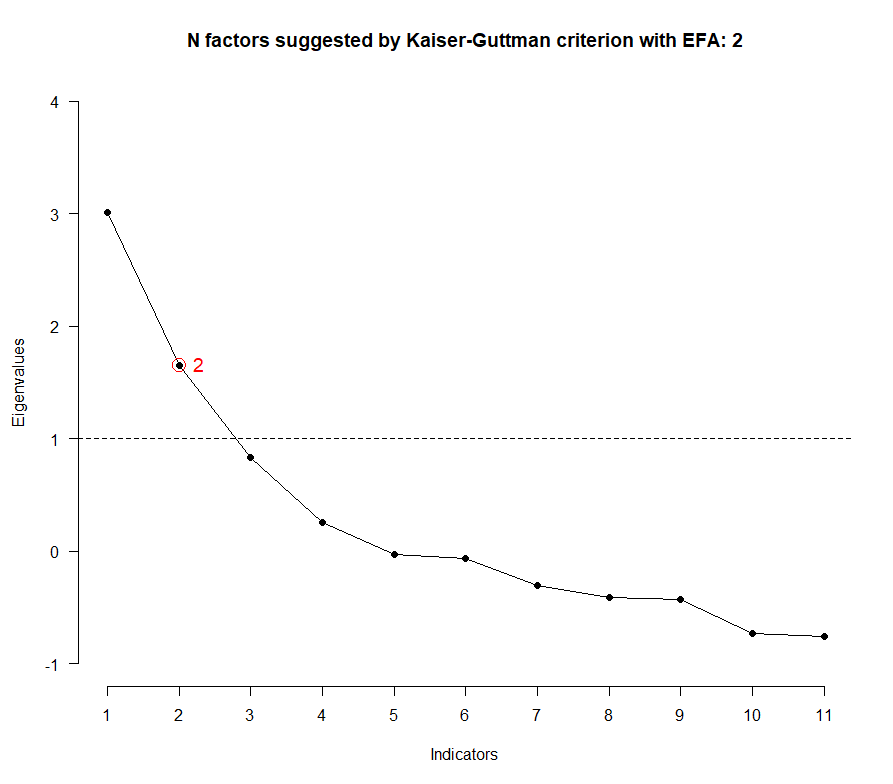
Exploring possible factors
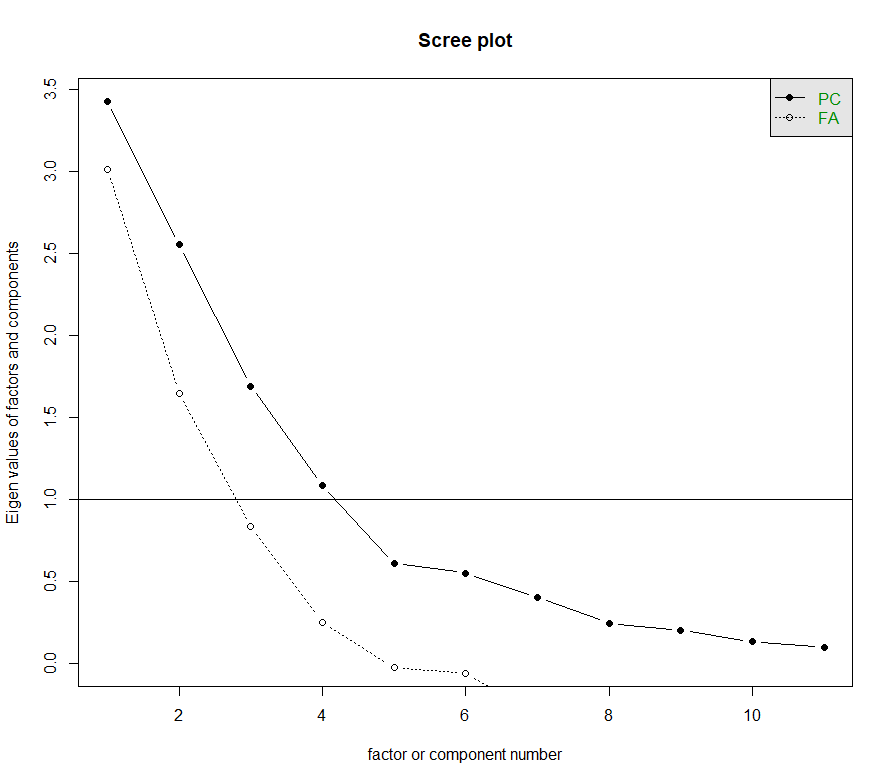
Exploring possible factors
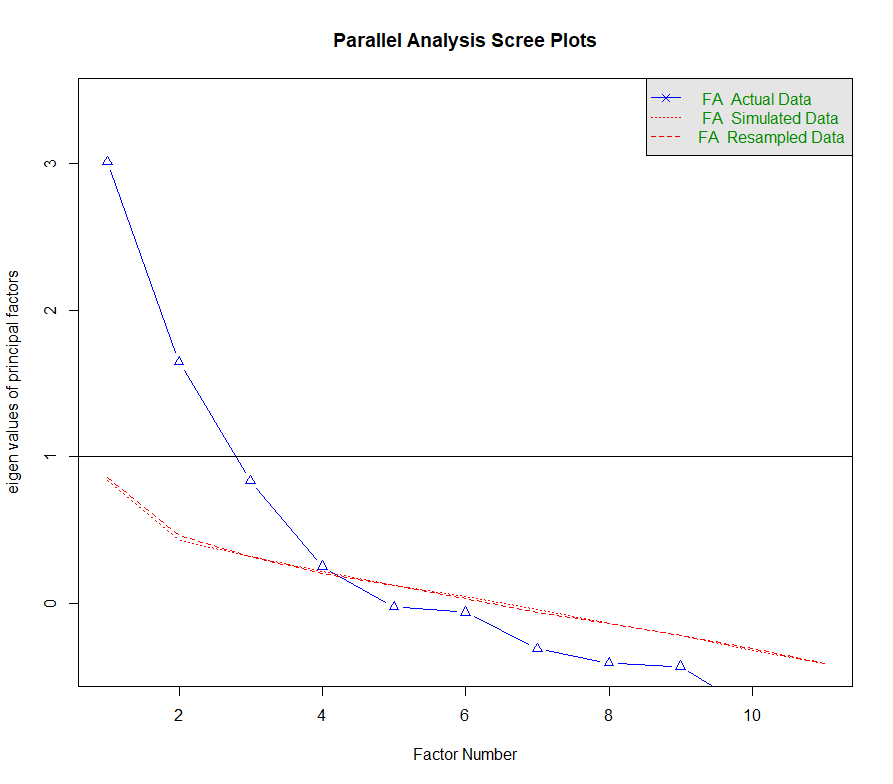
3. Parallel Test
- Generates a large number of simulated dataset.
- Each simulated dataset is factor analyzed.
- Results is the average eigenvalues across simulation.
- Values are then compared to the eigenvalues extracted from the original dataset.
- All factors with eigenvalues above those average eigenvalues are retained.
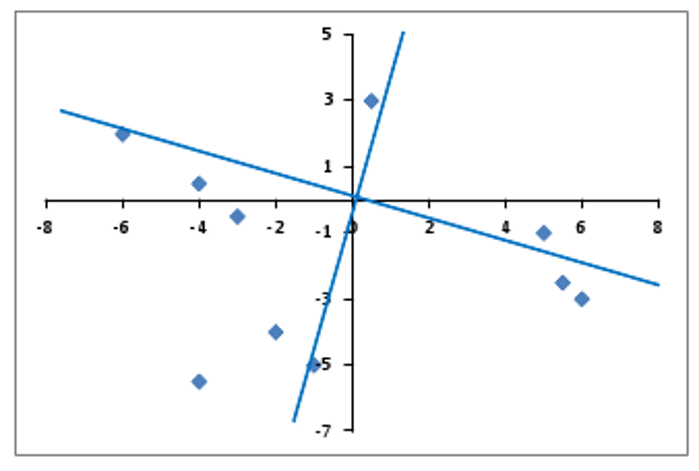
Factor rotation
Why do factor rotation?
To simplify the complexity of factor loadings.
Distribute the loading more clearly into the factors.
Facilitate interpretation.
Factor rotation
fa_rotated <- fa(r = data, nfactors = 4,rotate = "varimax")
par(mfrow = c(2, 1))
plot(fa_unrotated$loadings[,1],
fa_unrotated$loadings[,2],
xlab = "Factor 1",
ylab = "Factor 2",
ylim = c(-1, 1),
xlim = c(-1, 1),
main = "No rotation",
pch = 19,
cex = 2,
col = "#6c757d")
abline(h=0, v=0)
text(fa_unrotated$loadings[,1],
fa_unrotated$loadings[,2],
labels = rownames(fa_unrotated$loadings),
pos = 4, cex = 1)
plot(fa_rotated$loadings[,1],
fa_rotated$loadings[,2],
xlab = "Factor 1",
ylab = "Factor 2",
ylim = c(-1, 1),
xlim = c(-1, 1),
main = "With rotation",
pch = 19,
cex = 2,
col = "#6c757d")
abline(h=0, v=0)
text(fa_rotated$loadings[,1],
fa_rotated$loadings[,2],
labels = rownames(fa_unrotated$loadings),
pos = 4, cex = 1)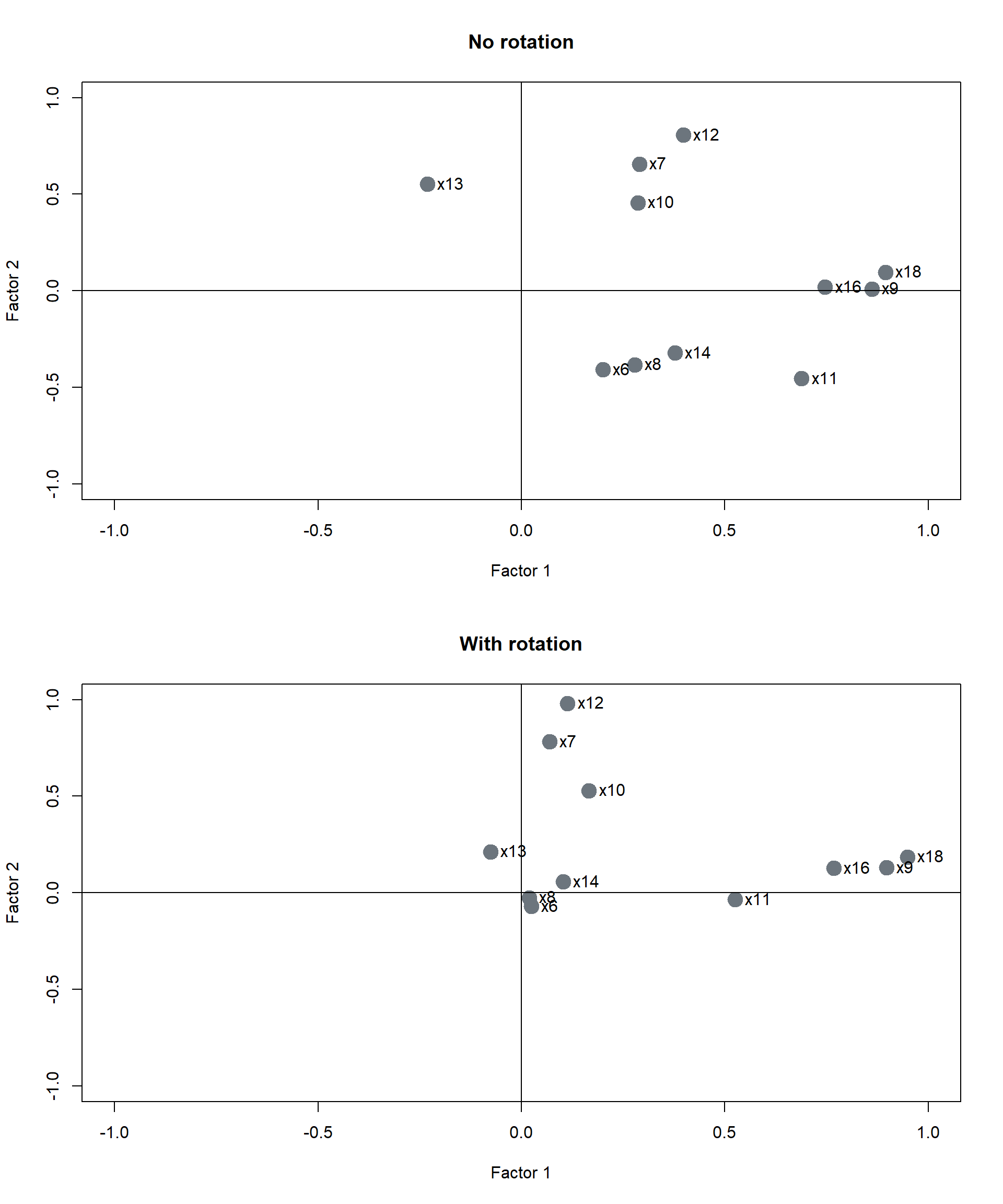
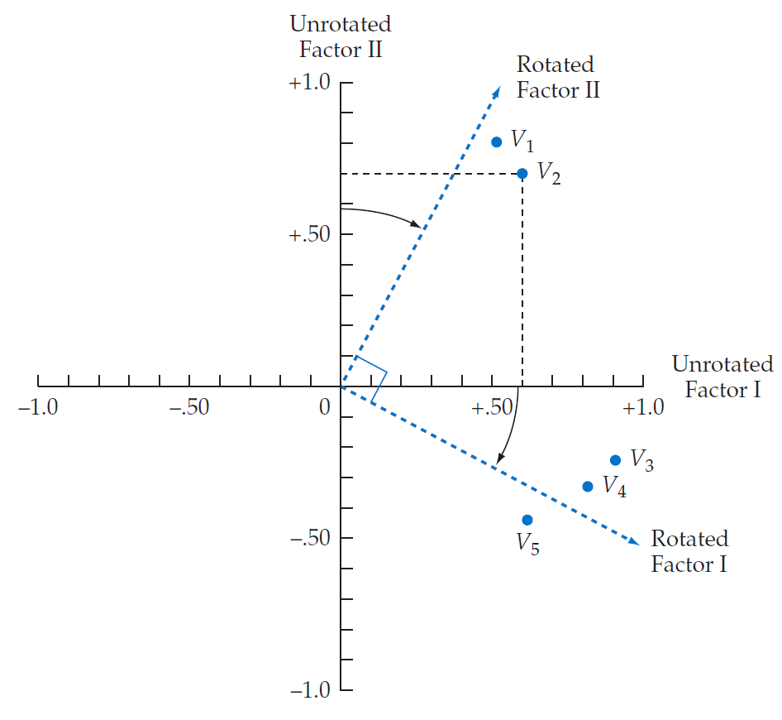
Factor rotation
Orthogonal rotation
axes are maintained at 90 degrees
orthogonal rotation methods
Varimax - most commonly used
Quartimax
Equimax
Check-out some of these references
Factor rotation
Orthogonal rotation
fa_varimax <- fa(r = data, nfactors = 4,rotate = "varimax")
fa_quartimax <- fa(r = data, nfactors = 4,rotate = "quartimax")
fa_equamax <- fa(r = data, nfactors = 4,rotate = "equamax")
par(mfrow = c(2, 2))
plot(fa_unrotated$loadings[,1],
fa_unrotated$loadings[,2],
xlab = "Factor 1",
ylab = "Factor 2",
ylim = c(-1, 1),
xlim = c(-1, 1),
main = "No rotation",
cex.main = 3,
pch = 19,
cex = 4,
col = "#6c757d")
abline(h=0, v=0)
text(fa_unrotated$loadings[,1],
fa_unrotated$loadings[,2],
labels = rownames(fa_unrotated$loadings),
pos = 4, cex = 2)
plot(fa_varimax$loadings[,1],
fa_varimax$loadings[,2],
xlab = "Factor 1",
ylab = "Factor 2",
ylim = c(-1, 1),
xlim = c(-1, 1),
main = "Varimax",
cex.main = 3,
pch = 19,
cex = 4,
col = "#6c757d")
abline(h=0, v=0)
text(fa_varimax$loadings[,1],
fa_varimax$loadings[,2],
labels = rownames(fa_varimax$loadings),
pos = 4, cex = 2)
plot(fa_quartimax$loadings[,1],
fa_quartimax$loadings[,2],
xlab = "Factor 1",
ylab = "Factor 2",
ylim = c(-1, 1),
xlim = c(-1, 1),
main = "Quartimax",
cex.main = 3,
pch = 19,
cex = 4,
col = "#6c757d")
abline(h=0, v=0)
text(fa_quartimax$loadings[,1],
fa_quartimax$loadings[,2],
labels = rownames(fa_quartimax$loadings),
pos = 4, cex = 2)
plot(fa_equamax$loadings[,1],
fa_equamax$loadings[,2],
xlab = "Factor 1",
ylab = "Factor 2",
ylim = c(-1, 1),
xlim = c(-1, 1),
main = "Equamax",
cex.main = 3,
pch = 19,
cex = 4,
col = "#6c757d")
abline(h=0, v=0)
text(fa_equamax$loadings[,1],
fa_equamax$loadings[,2],
labels = rownames(fa_equamax$loadings),
pos = 4, cex = 2)
Factor rotation
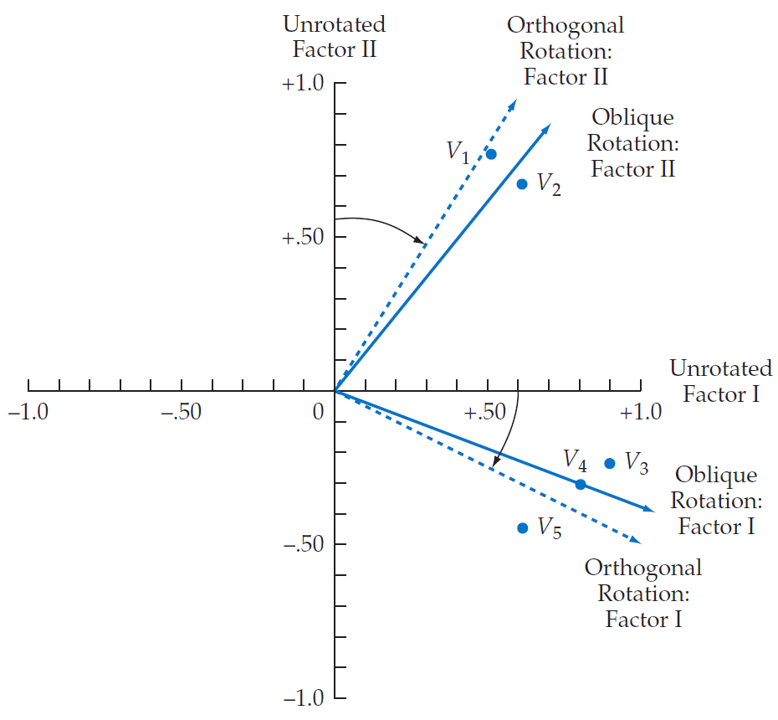
Oblique rotation rotation
allow correlated factors
suited to the goal of theoretically meaningful constructs
oblique rotation methods
Promax
Oblimin
Factor rotation
Oblique rotation
fa_promax <- fa(r = data, nfactors = 4,rotate = "promax")
fa_oblimin <- fa(r = data, nfactors = 4,rotate = "oblimin")
par(mfrow = c(1, 3))
plot(fa_unrotated$loadings[,1],
fa_unrotated$loadings[,2],
xlab = "Factor 1",
ylab = "Factor 2",
ylim = c(-1, 1),
xlim = c(-1, 1),
main = "No rotation",
pch = 19,
col = "#6c757d")
abline(h=0, v=0)
text(fa_unrotated$loadings[,1],
fa_unrotated$loadings[,2],
labels = rownames(fa_unrotated$loadings),
pos = 4, cex = 0.5)
plot(fa_promax$loadings[,1],
fa_promax$loadings[,2],
xlab = "Factor 1",
ylab = "Factor 2",
ylim = c(-1, 1),
xlim = c(-1, 1),
main = "Promax",
pch = 19,
col = "#6c757d")
abline(h=0, v=0)
text(fa_promax$loadings[,1],
fa_promax$loadings[,2],
labels = rownames(fa_promax$loadings),
pos = 4, cex = 0.5)
plot(fa_oblimin$loadings[,1],
fa_oblimin$loadings[,2],
xlab = "Factor 1",
ylab = "Factor 2",
ylim = c(-1, 1),
xlim = c(-1, 1),
main = "Oblimin",
pch = 19,
col = "#6c757d")
abline(h=0, v=0)
text(fa_oblimin$loadings[,1],
fa_oblimin$loadings[,2],
labels = rownames(fa_oblimin$loadings),
pos = 4, cex = 0.5)

Thank you!
